IMAGE DATASET FOR MACHINE LEARNING
Collecting Image Data for Sophisticated Computer Vision Applications
Image data collection is the process of gathering and compiling a set of images for various purposes such as machine learning, computer vision, and data analysis.

Gather varied human images from around the world on a global scale
Our worldwide image dataset encompasses a variety of facial expressions and ethnicities, improving AI model recognition and comprehension of faces worldwide.
VIDEO DATASET COLLECTION SERVICES
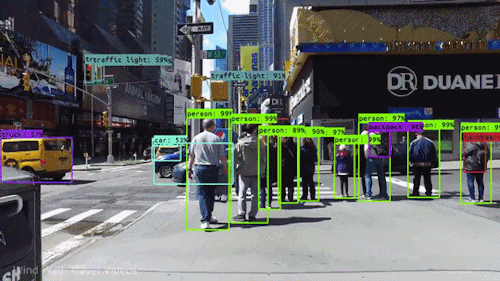
Fiyanex Video Dataset Compilation: Precision Across Each Frame
Fiyanex specializes in capturing and refining video content, meticulously analyzing each frame, and labelling objects for precise machine recognition, crafting tailored datasets for specific AI and machine learning needs.
Global Proficiency in Varied Video Data Compilation
Fiyanex provides a globally acquired video dataset customized for machine learning, covering CCTV footage, traffic videos, and surveillance recordings. With our advanced Video Data Collection Tool, we guarantee accuracy in both collection and annotation, empowering your models with superior datasets for unmatched performance.

SPEECH DATASET COLLECTION SERVICE
Capturing the Essence of Eloquent Speech: Gathering Speech Data
At Fiyanex, our expertise lies in assembling top-notch speech datasets customized for the varied requirements of the AI and machine learning sector. Our broad language inclusivity and diverse recording settings guarantee the versatility and comprehensiveness of our datasets.


Worldwide Proficiency in Varied Speech Data Acquisition
We gather global Speech Data crucial for AI advancements worldwide. Our proficiency covers Text-to-Speech, Multilingual Audio, Automatic Speech Recognition, Virtual Assistants, and more, establishing us as pioneers in acquiring comprehensive auditory datasets.
TEXT DATASET COLLECTION SERVICE

Gathering Textual Information for Sophisticated Natural Language Processing
Fiyanex passionately delves into diverse unstructured text sources, extracting insights from medical reports, insurance claims, and financial records. Committed to pioneering human-like language tech, Fiyanex meticulously collects and incorporates varied text data, leaving no stone unturned for top-notch NLP dataset creation through exhaustive model training.
Worldwide Proficiency in Varied Text Data Acquisition
We specialize in globally sourcing diverse datasets for AI and ML advancements. Our repertoire includes Receipt Data, Ticket Datasets, EHR & Physician Dictation Transcripts, Documents, Handwritten Data, OCR Training, and Chatbot Training Data. Leveraging these enriches AI projects for sharper, globally adaptable models with improved responsiveness.
